
In the previous post I have outlined three possibilities for approximating the likelihood function of a state space model (SSM). That post is a required read to follow the topics treated here. I concluded with sequential importance sampling (SIS), which provides a convenient online strategy. However, in some cases SIS suffers from some numerical problems that I will address here. The key concept is the introduction of a resampling step. Then I introduce the simplest example of a sequential Monte Carlo (SMC) algorithm, the bootstrap filter. Recommendations on how to make best use of resampling are discussed.
Sequential Importance Sampling with Resampling
An important result derived in the previous post is the sequential update of the importance weights. That is, by denoting with 


The weights update allows for an online approximation of the likelihood function of parameters 
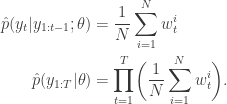
At this point, an approximate maximum likelihood estimate can be obtained by searching for the following (typically using a numerical optimizer)

or 
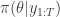
Actually, while the procedure above can be successful, in general depending on the type of data and the adequacy of the model we employ to “fit” the data, some crucial problems can occur.
Particle degeneracy: the convenient representation of 


This outlier could have been produced by an unusual statistical fluctuation, and at time 
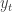
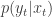

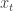
Say that I choose as importance density the transition density of the latent process, that is I set 
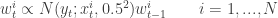
with some abuse of notation. Now, for the given choice of proposal density (and if I have been employing a model appropriate for the data) then at the previous time instant 43, most particles will have values somewhere around 30 (see the y-axis in the figure), and we could expect that if 
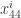




The phenomenon were most particles have very small weights is called particle degeneracy and for many years has prevented these Monte Carlo strategies from being effective. When particle degeneracy occurs the likelihood approximation is poor with a large variance, because the numerical calculation of the underlying integrals is essentially performed by the few particles with non-zero weight.
The striking idea that changed everything is the introduction of a resampling step, whose importance in sequential Monte Carlo was first studied in Gordon et al (1993), based on ideas from Rubin (1987). The idea is simple and ingenious and has revolutionised the practical application of sequential methods. The resulting algorithm is the “sequential importance sampling with resampling” (SISR) but we will just call it a sequential Monte Carlo algorithm.
Resampling
The resampling idea is to get rid in a principled way of the particles with small weight and multiply the particles with large weight. Recall that generating particles is about exploring regions of the space where the integral has most of its mass. Therefore, we want to focus the computational effort on the “promising” parts of the space. This is easily accomplished if we “propagate forward” from the promising particles, which are those with a non-negligible weight
- Normalize the weights to sum to 1, that is compute
.
- interpret
as the probability associated to
. If this can help, imagine the particles to be balls contained in an urn: some balls are large (large
- Resampling: sample
times with replacement from the weighted set, to generate a new sample of
then put the ball back in the urn and repeat the extraction and recording for
- Replace the old particles with the new ones
. Basically, we empty the urn then fill it up again with copies of the balls having the recorded indices. Say that we have extracted index
five times, we put in the urn five copies of the ball with index
- Reset all the unnormalised weights to
(the resampling has destroyed the information on “how” we reached time
).
Since resampling is done with replacement, a particle with a large weight is likely to be drawn multiple times. Particles with very small weights are not likely to be drawn at all. Nice!
The reason why performing a resampling step is not only a numerically convenient trick to overcome (sometimes!) particle degeneracy, but is also probabilistically allowed (i.e. it preserves our goal to obtain an approximation targeting 
Forward propagation
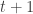 , that is we propagate forward the state of the system by simulating particles
, that is we propagate forward the state of the system by simulating particles  . And how do we perform this step? We take advantage of the important particles we have just resampled, using the importance density to compute the move
. And how do we perform this step? We take advantage of the important particles we have just resampled, using the importance density to compute the move 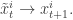 might originate from a common “parent”
might originate from a common “parent”  . For illustration see the picture below.
. For illustration see the picture below.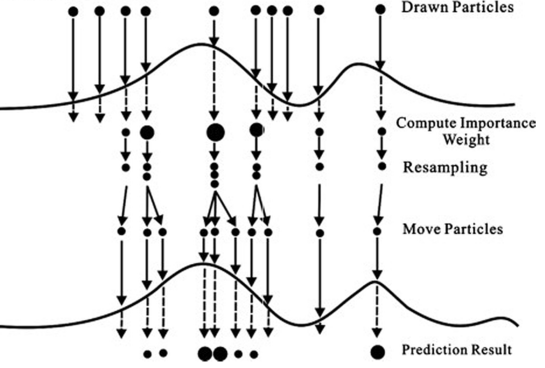
Read the picture from top to bottom: we start with particles having all the same size, which means they have equal weight 

The bootstrap filter
The bootstrap filter is the simplest example of a sequential importance sampling with resampling (SISR) algorithm. It is the “simplest” application of SISR because it assumes
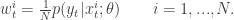
Notice that in the equation above we have an equality, instead of a proportionality, since after resampling we set weights to be all equal to 
This approach is certainly very practical and appealing, but it comes at a cost. Generating particles from 
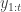
So here is the bootstrap filter in detail.
- At
(initialize)
and assign
, for all
.
- At the current
.
- From the current sample of particles, resample with replacement
.
- Propagate forward
, for all
- Compute
and normalise weights
.
- Set
and if
go to step 2 otherwise go to 7.
- Return
.
Recall that 


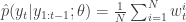

The seven steps above are the simplest version of a bootstrap filter, where the resampling is performed at every
A standard way to proceed is to resample only when necessary, as given by a measure of potential degeneracy of the sequential Monte Carlo approximation, such as the effective sample size (Liu and Chen, 1998). The effective sample size takes values between 1 and 
Finally notice that SISR (and the bootstrap filter) returns an unbiased estimate of the likelihood function. This is completely unintuitive and not trivial to prove. I will go back to this point in a future post.
Implement resampling
Coding your own version of a resampling scheme should not be necessary: popular statistical software will probably have built-in functions implementing several resampling algorithms. To my knowledge, the four most popular resampling schemes are: residual resampling, stratified resampling, systematic resampling and multinomial resampling. I mentioned above that resampling adds additional unwanted variability to the likelihood approximation. Moreover, different schemes produce different variability. Multinomial resampling is the one that gives the worse performance in terms of added variance, while residual, stratified and systematic resampling are about equivalent, though systematic resampling is often preferred because easier to implement and fast. See Douc et al. 2005 and Hol et al. 2006.
Summary
I have addressed the problem known as “particles degeneracy” affecting sequential importance sampling algorithms. I have introduced the concept of resampling, and when to perform said resampling. This produces a sequential importance sampling resampling (SISR) algorithm. Then I have introduced the simplest example of SISR, the bootstrap filter. Finally, I have briefly mentioned some results pertaining resampling schemes.
We now have a partial (though useful starting point for further self study) introduction to particle filters / sequential Monte Carlo methods for approximating the likelihood function of a state space model. We are now ready to consider Bayesian parameter inference, including practical examples.
Further reading
- Darren Wilkinson’s blog is a great resource. I recommend following his blog for his insightful and clearly written posts. In this case see his description of importance sampling, resampling and the bootstrap filter.
- Chapter 11 in Simo Särkkä (2013) Bayesian Filtering and Smoothing, Cambridge University Press. Notice a PDF version is freely available at the author’s webpage. Companion software is available at the publisher’s page (see the Resources tab).
- Review paper by Doucet and Johansen (2008). A Tutorial on Particle Filtering and Smoothing: Fifteen years later.

Just wanted to say these posts were extremely helpful
– Grateful reader
LikeLike
Exactly a nice blog! detail derivation, thorough discussion!
LikeLike